- Published on
Machine Learning - Decision Tree
- Authors
- Name
- Soulaimane Yahya
- @soulaimaneyh


In this article, we will explain to you how to make a "Decision Tree". A Decision Tree is a flowchart that facilitates decision-making based on past experiences.
Machine Learning - Decision Tree
In this article, a person will try to decide whether or not to purchase a specific product based on various factors, age, gender and income.
| Age | Gender | Income | Purchase |
|---|---|---|---|
| 25 | Male | 35000 | No |
| 30 | Female | 30000 | Yes |
| 35 | Female | 32000 | Yes |
| 20 | Male | 40000 | Yes |
| 40 | Male | 45000 | Yes |
| 45 | Female | 28000 | No |
| 55 | Male | 55000 | Yes |
| 50 | Female | 26000 | No |
| 22 | Male | 42000 | Yes |
| 38 | Female | 58000 | Yes |
Now, based on this data set, Python can create a decision tree that can be used to decide if any new product will be purchased.
How Does it Work?
First, read the dataset with pandas:
import pandas
df = pandas.read_csv("data.csv")
print(df)To make a decision tree, all data has to be numerical.
We have to convert the non numerical columns 'Gender' and 'Purchase' into numerical values.
Pandas has a map() method that takes a dictionary with information on how to convert the values.
d = {'Female': 0, 'Male': 1}Means convert the values 'Female' to 0, 'Male' to 1.
d = {'Female': 0, 'Male': 1}
df['Gender'] = df['Gender'].map(d)
d = {'Yes': 1, 'No': 0}
df['Purchase'] = df['Purchase'].map(d)
print(df)Then we have to separate the feature columns from the target column.
The feature columns are the columns that we try to predict from, and the target column is the column with the values we try to predict.
X is the feature columns, Y is the target column:
features = ['Age', 'Gender', 'Income']
X = df[features]
Y = df['Purchase']
print(X)
print(Y)Now we can create the actual decision tree, fit it with our details. Start by importing the modules we need:
Create and display a Decision Tree:
import sys
import matplotlib
matplotlib.use('Agg')
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
def main():
# Convert data to DataFrame
df = pd.read_csv("data.csv")
# Map categorical variables to numerical values
d = {'Female': 0, 'Male': 1}
df['Gender'] = df['Gender'].map(d)
d = {'Yes': 1, 'No': 0}
df['Purchase'] = df['Purchase'].map(d)
# Define features and target variable
features = ['Age', 'Gender', 'Income']
X = df[features]
Y = df['Purchase']
# Train Decision Tree Classifier
dtree = DecisionTreeClassifier()
dtree = dtree.fit(X, Y)
# Plot decision tree
plt.figure(figsize=(10, 7))
plot_tree(dtree, feature_names=features, filled=True)
plt.savefig("decision_tree.png")
plt.show()
if __name__ == "__main__":
main()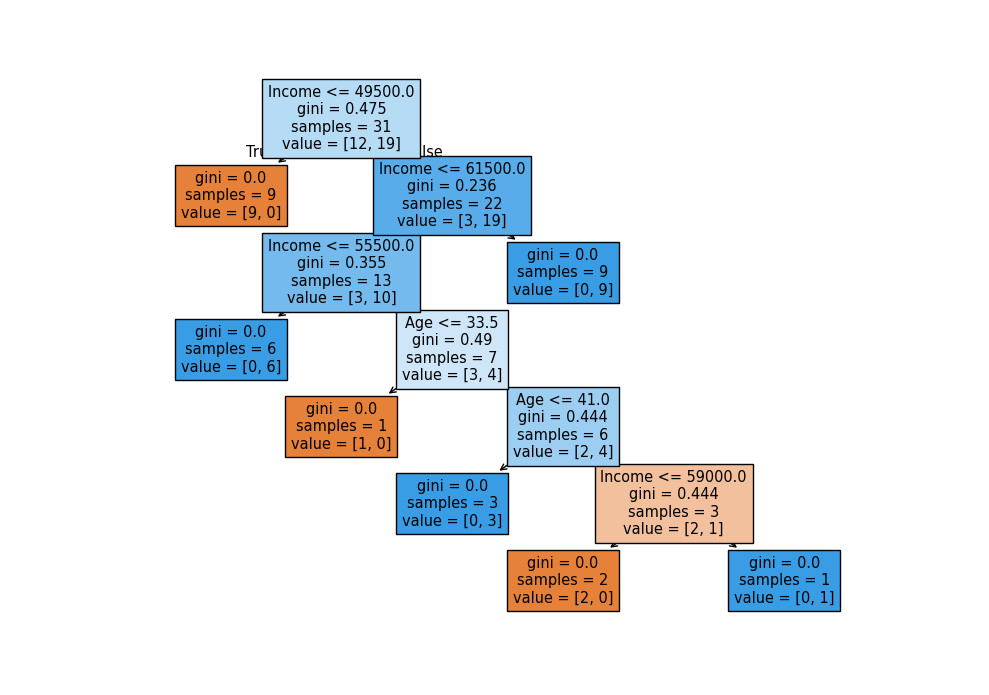
Predict Values
We can use the Decision Tree to predict new values.
Example: Should I buy product with;
Use predict() method to predict new values:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
def main():
# Convert data to DataFrame
df = pd.read_csv("data.csv")
# Map categorical variables to numerical values
d = {'Female': 0, 'Male': 1}
df['Gender'] = df['Gender'].map(d)
d = {'Yes': 1, 'No': 0}
df['Purchase'] = df['Purchase'].map(d)
# Define features and target variable
features = ['Age', 'Gender', 'Income']
X = df[features]
Y = df['Purchase']
# Train Decision Tree Classifier
dtree = DecisionTreeClassifier()
dtree = dtree.fit(X, Y)
# Predict
prediction = dtree.predict([[30, 1, 50000]])
print("Prediction:", prediction)
print("[1] means 'Yes'")
print("[0] means 'No'")
if __name__ == "__main__":
main()What would the answer be if the income lower than 20000?
print(dtree.predict([[50, 0, 20000]]))INFO
Different Results
You will see that the Decision Tree gives you different results if you run it enough times, even if you feed it with the same data.
That is because the Decision Tree does not give us a 100% certain answer. It is based on the probability of an outcome, and the answer will vary.